RTX 50顯卡評(píng)測(cè)背后的秘密武器:深度剖析AI基準(zhǔn)測(cè)試
引言:
科技的海潮滾滾向前,每一次硬件的迭代都不僅僅是數(shù)字的更改,更是應(yīng)用處景的深刻變革。近期兩大年夜顯卡巨擘紛紛宣布了新一代的NVIDIA GeForce RTX 50系列與AMD Radeon RX 9070系列花費(fèi)級(jí)顯卡,激發(fā)了玩家、內(nèi)容創(chuàng)作者,甚至是專業(yè)人士的熱烈評(píng)論辯論。與以往不合的是,除了傳統(tǒng)的游戲機(jī)能晉升外,一個(gè)愈發(fā)洪亮的關(guān)鍵詞成為宣布會(huì)和后續(xù)分析的核心――人工智能(AI)算力。
![]()
TOPS/FLOPS(理論峰值算力):
我們清楚地看到,花費(fèi)級(jí)顯卡的設(shè)計(jì)理念正在經(jīng)歷一場(chǎng)深刻的演變。它們不再僅僅是驅(qū)動(dòng)極致游戲畫(huà)面的“游戲卡”,而是越來(lái)越多地承擔(dān)起內(nèi)容創(chuàng)作加快、復(fù)雜科學(xué)計(jì)算,甚至驅(qū)動(dòng)前沿AI模型的重?fù)?dān)。

從視頻編輯中的智能對(duì)象摳圖、音頻降噪,到3D襯著中的AI幫助優(yōu)化,再到本地運(yùn)行大年夜型說(shuō)話模型(LLM)的潛力,AI正以前所未有的速度滲入滲出到我們數(shù)字生活的方方面面。而這一切,都對(duì)底層硬件的AI處理才能提出了更高的請(qǐng)求。

各大年夜科技媒體和自力評(píng)測(cè)機(jī)構(gòu)對(duì)這些新生代顯卡的評(píng)測(cè)申報(bào)中,除了慣例的3DMark、游戲幀率等數(shù)據(jù)外,一系列專業(yè)的AI基準(zhǔn)測(cè)試對(duì)象及其得分也占據(jù)了顯要地位。這些對(duì)象,如MLPerf、UL Procyon AI Inference Benchmark等,正成為衡量顯卡“聰明”程度的標(biāo)尺。那么,這些看似復(fù)雜的AI測(cè)試對(duì)象畢竟是什么?它們是若何工作的?我們又該若何解讀其測(cè)試成果,從而精確評(píng)估一款顯卡在AI時(shí)代的真實(shí)價(jià)值?下面我們將會(huì)應(yīng)用技嘉GeForce RTX 5070 Ti GAMING OC 魔鷹 16G顯卡為大年夜家進(jìn)行一系列的實(shí)測(cè)與詳解。
花費(fèi)級(jí)顯卡周全擁抱AI
AI,特別是深度進(jìn)修,其核心運(yùn)算大年夜多涉及大年夜范圍的矩陣和向量運(yùn)算。例如,神經(jīng)收集的練習(xí)和推理過(guò)程,本質(zhì)上就是對(duì)海量數(shù)據(jù)進(jìn)行反復(fù)的、相對(duì)簡(jiǎn)單的數(shù)學(xué)計(jì)算。GPU最初為圖形襯著而設(shè)計(jì),其核心優(yōu)勢(shì)在于擁稀有千個(gè)小型計(jì)算核心(如NVIDIA的CUDA核心或AMD的Stream Processors),可以或許同時(shí)履行大年夜量并行計(jì)算義務(wù)(SIMD - Single Instruction, Multiple Data)。這種架構(gòu)與AI算法的需求不約而同,使得GPU在處理這些義務(wù)時(shí)遠(yuǎn)比CPU(中心處理器,其核心數(shù)量較少,但單個(gè)核心功能更強(qiáng)大年夜,更善于復(fù)雜的邏輯控制和串行義務(wù))更高效。

尤其是近年來(lái),幾大年夜顯卡上游廠商靈敏地捕獲到了AI的趨勢(shì),開(kāi)端在GPU芯片中集成專為AI計(jì)算優(yōu)化的硬件單位。個(gè)中NVIDIA的Tensor Cores就是個(gè)中的佼佼者,它們針對(duì)深度進(jìn)修中常見(jiàn)的混淆精度矩陣乘法運(yùn)算進(jìn)行了特別優(yōu)化,可以或許大年夜幅晉升特定AI工作負(fù)載的吞吐量。
具體機(jī)能展示會(huì)在答復(fù)內(nèi)容的最后小字出現(xiàn),如上圖我們拿技嘉GeForce RTX 5070 Ti GAMING OC 魔鷹 16G顯卡做的測(cè)試速度為66.62 tok/sec與0.30s TTFT,并且其顯存占用為11GB。

拿新一代的花費(fèi)顯卡技嘉GeForce RTX 5070 Ti GAMING OC 魔鷹 16G顯卡規(guī)格來(lái)說(shuō),同樣是采取了TSMC同新一代的TSMC 4nm 4N制造工藝,然則其核心規(guī)格與機(jī)能都有著明顯的增長(zhǎng)。尤其是AI機(jī)能方面,有著長(zhǎng)足的晉升,分別達(dá)到了:Shader TFLOPS(43.9);FP4 AI TOPS(1406),AI TOPS(703),以及RT FLOPS(133.2)。
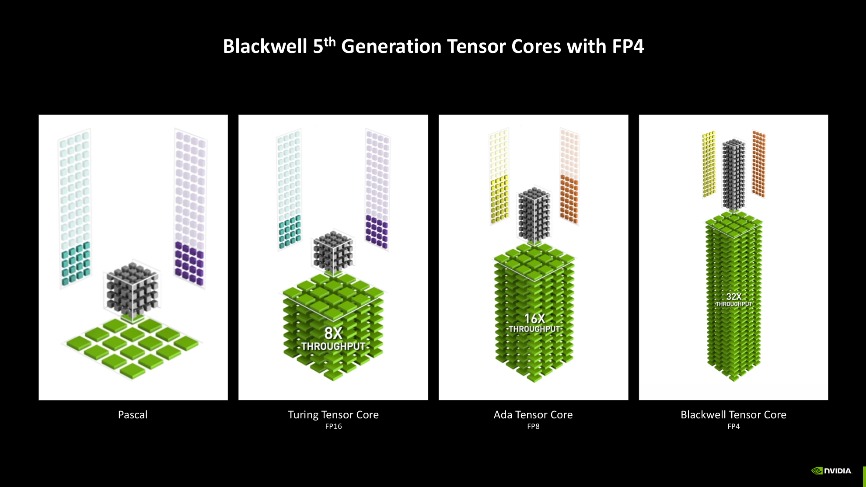
個(gè)中GeForce RTX 50系列參加了對(duì)FP4精度模型加快處理的支撐,相較FP8精度,可以或許實(shí)現(xiàn)更快的生成速度,同時(shí)顯存占用也更低。

LM Studio
并且FP4精度模型生成的圖片也異常能打,從下圖就能看出來(lái),其與FP8生成的圖片幾乎沒(méi)有差別,無(wú)論是對(duì)關(guān)鍵詞的懂得照樣圖像的質(zhì)量,都異常有保障,新時(shí)代AIGC玩家的最佳選擇了。
AI機(jī)能的關(guān)鍵指標(biāo)
在查看AI測(cè)試對(duì)象的申報(bào)時(shí),我們會(huì)碰到一系列專業(yè)術(shù)語(yǔ)和指標(biāo)。懂得它們的含義至關(guān)重要:
TOPS (Tera Operations Per Second): 每秒萬(wàn)億次運(yùn)算。在AI范疇,平日指INT8(8位整數(shù))或INT4等低精度整數(shù)運(yùn)算才能,因?yàn)楹芏郃I推理義務(wù)可以在較低精度下完成而幾乎不損掉精確性,同時(shí)大年夜幅晉升速度和效力。
重要性與局限性:TOPS/FLOPS作為衡量GPU理論計(jì)算潛力的關(guān)鍵指標(biāo),平日由芯片制造商頒布。例如,NVIDIA會(huì)強(qiáng)調(diào)其Tensor Core的FP16或INT8 TOPS算力,而RTX 50系列顯卡支撐FP4,是以在推廣中我們也會(huì)看到如許的數(shù)值表示。然而,理論峰值并不等同于實(shí)際機(jī)能。實(shí)際機(jī)能受到內(nèi)存帶寬、緩存效力、驅(qū)動(dòng)優(yōu)化、軟件[IT江湖]生態(tài)以及具體AI模型的計(jì)算特點(diǎn)等多種身分的影響。
吞吐量 (Throughput):
指單位時(shí)光內(nèi)體系可以或許處理的AI義務(wù)數(shù)量。例如,在MLPerf Inference的Offline場(chǎng)景下,吞吐量平日以“每秒處理樣本數(shù)”(Samples per second)來(lái)衡量。對(duì)于圖像生成,則可能是“每秒生成圖像數(shù)”或“每秒迭代次數(shù)”(iterations/sec)。高吞吐量意味著顯卡可以或許高效處理大年夜范圍AI義務(wù)。
延遲 (Latency):
指完成單個(gè)AI義務(wù)所需的時(shí)光,平日以毫秒(ms)為單位。低延遲對(duì)于及時(shí)AI應(yīng)用至關(guān)重要,如語(yǔ)音辨認(rèn)、及時(shí)翻譯、游戲中的AI互動(dòng)等。MLPerf Inference的SingleStream場(chǎng)景就特別存眷延遲。
精確性 (Accuracy):
固然基準(zhǔn)測(cè)試重要存眷速度,但AI模型的輸出質(zhì)量同樣重要。MLPerf等標(biāo)準(zhǔn)基準(zhǔn)會(huì)設(shè)定一個(gè)目標(biāo)精確率,測(cè)試體系須要在達(dá)到該精確率的前提下比拼速度。假如為了尋求速度而就義過(guò)多精確性,那么測(cè)試成果的意義就會(huì)大年夜打扣頭。
能效比 (Performance per Watt):
指GPU在消費(fèi)單位功率(瓦特)的情況下所能供給的AI算力。跟著AI計(jì)算需求的增長(zhǎng),功耗和散熱成為重要考量。高能效比意味著顯卡在供給強(qiáng)大年夜AI機(jī)能的同時(shí),更為節(jié)能環(huán)保,對(duì)電源和散熱體系的請(qǐng)求也更友愛(ài)。這對(duì)于筆記本電腦[IT江湖]和小型化PC尤為重要。
內(nèi)存帶寬與容量 (Memory Bandwidth & Capacity):
現(xiàn)代AI模型,特別是大年夜型說(shuō)話模型和高分辨率視覺(jué)模型,平日須要巨大年夜的顯存容量來(lái)存儲(chǔ)模型參數(shù)和中心數(shù)據(jù)。同時(shí),高速的顯存帶寬對(duì)于確保計(jì)算核心不因數(shù)據(jù)等待而余暇也至關(guān)重要。RTX 50和RX 9070系列估計(jì)會(huì)配備更大年夜容量、更高帶寬的顯存(如GDDR7),這將直接惠及其AI機(jī)能,尤其是在處理大年夜型模型時(shí)。
AI基準(zhǔn)測(cè)試對(duì)象概覽&測(cè)試
綜合性行業(yè)標(biāo)準(zhǔn)基準(zhǔn):MLPerf
MLPerf 是由 MLCommons 組織開(kāi)辟的一套行業(yè)標(biāo)準(zhǔn)基準(zhǔn)測(cè)試套件,旨在公平、客不雅地評(píng)估機(jī)械進(jìn)修(ML)體系的機(jī)能。MLPerf 的目標(biāo)是經(jīng)由過(guò)程標(biāo)準(zhǔn)化的測(cè)試辦法,為硬件平臺(tái)、軟件[IT江湖]框架和云辦事的機(jī)械進(jìn)修慣能供給可比較的指標(biāo),促進(jìn)人工智能(AI)技巧的立異和透明度。MLPerf 涵蓋了機(jī)械進(jìn)修慣命周期的兩個(gè)重要階段:
練習(xí)(Training):
MLPerf Training 基準(zhǔn)測(cè)試衡量體系練習(xí)機(jī)械進(jìn)修模型到特定質(zhì)量指標(biāo)(如目標(biāo)精確率)所需的時(shí)光。它測(cè)試模型、軟件[IT江湖]和硬件在練習(xí)過(guò)程中的綜合機(jī)能,實(shí)用于數(shù)據(jù)中間、云端和本地體系。
推理(Inference):
MLPerf Inference 基準(zhǔn)測(cè)試評(píng)估體系在已練習(xí)模型上處理新數(shù)據(jù)(推理)的速度和效力,覆蓋數(shù)據(jù)中間、邊沿設(shè)備和移動(dòng)設(shè)備等多種安排場(chǎng)景。它包含不合場(chǎng)景(如離線、辦事器、單流和多流)以模仿實(shí)際世界的應(yīng)用。
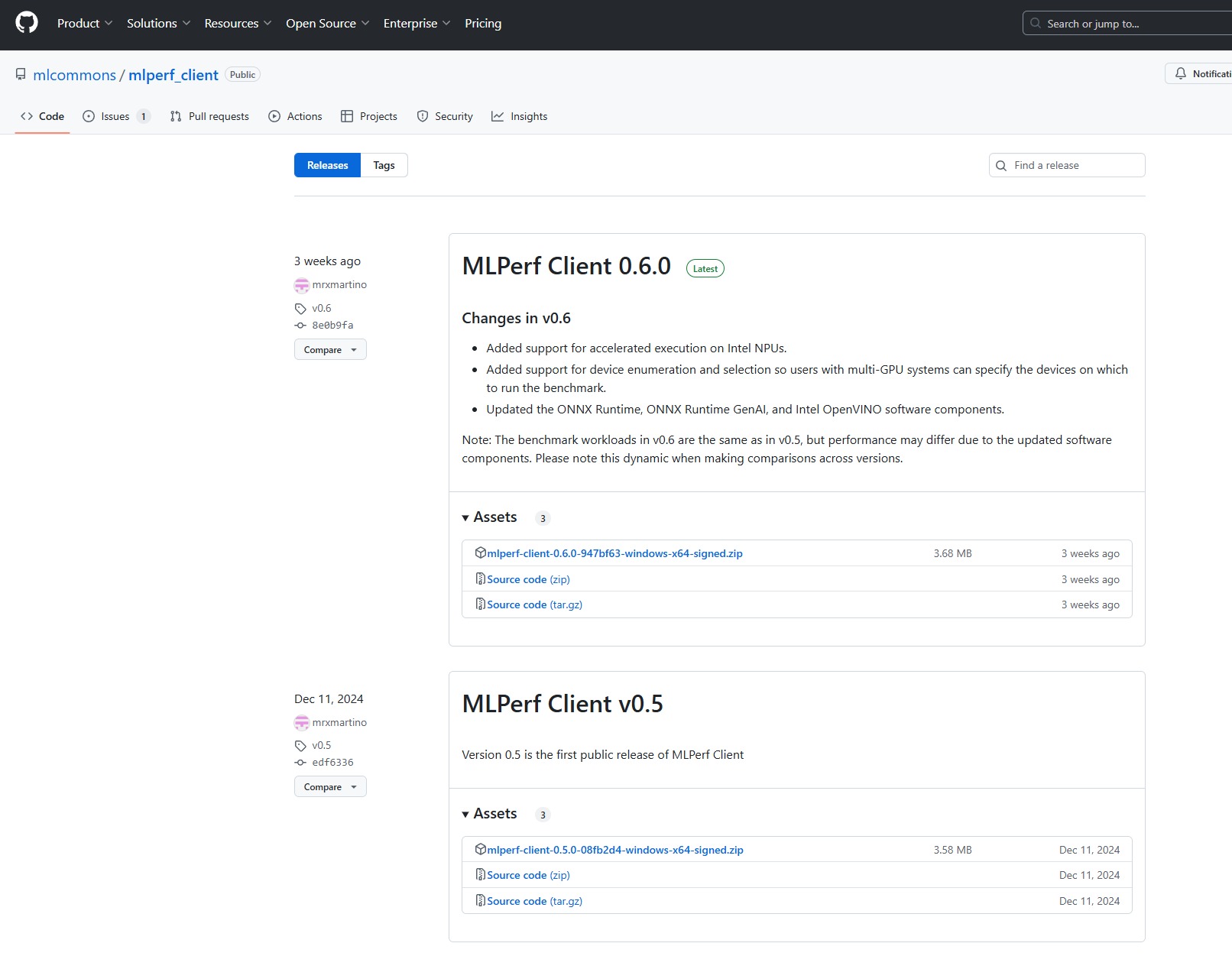
當(dāng)然MLPerf為我們供給了浩瀚的測(cè)試對(duì)象,然則這些都與我們沒(méi)關(guān),因?yàn)榉菍I(yè)人士與專業(yè)設(shè)備想玩轉(zhuǎn)這類軟件[IT江湖]并非一件輕易的事。而我們常用到的是MLPerf Client ,這是MLPerf基準(zhǔn)測(cè)試套件的一個(gè)分支,專門(mén)為客戶端設(shè)備(如筆記本電腦[IT江湖]、臺(tái)式機(jī)和工作站)上的機(jī)械進(jìn)修慣能評(píng)估而設(shè)計(jì)。
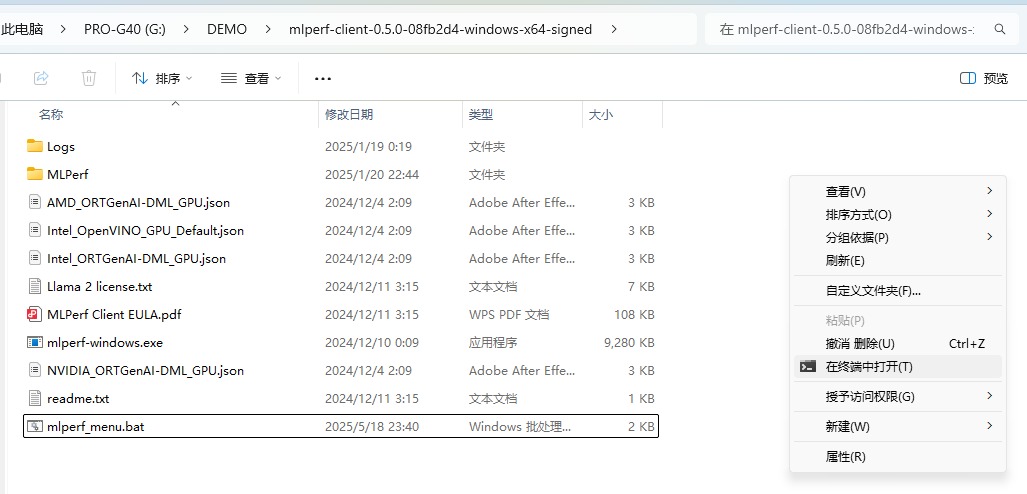
我們可以直接從GitHub上的MLPerf官方下載頁(yè)面中下載到最新版本的MLPerf Client,如上圖所示就是我們之前常用的MLPerf Client 0.5版本,今朝最新為MLPerf Client 0.6版本。
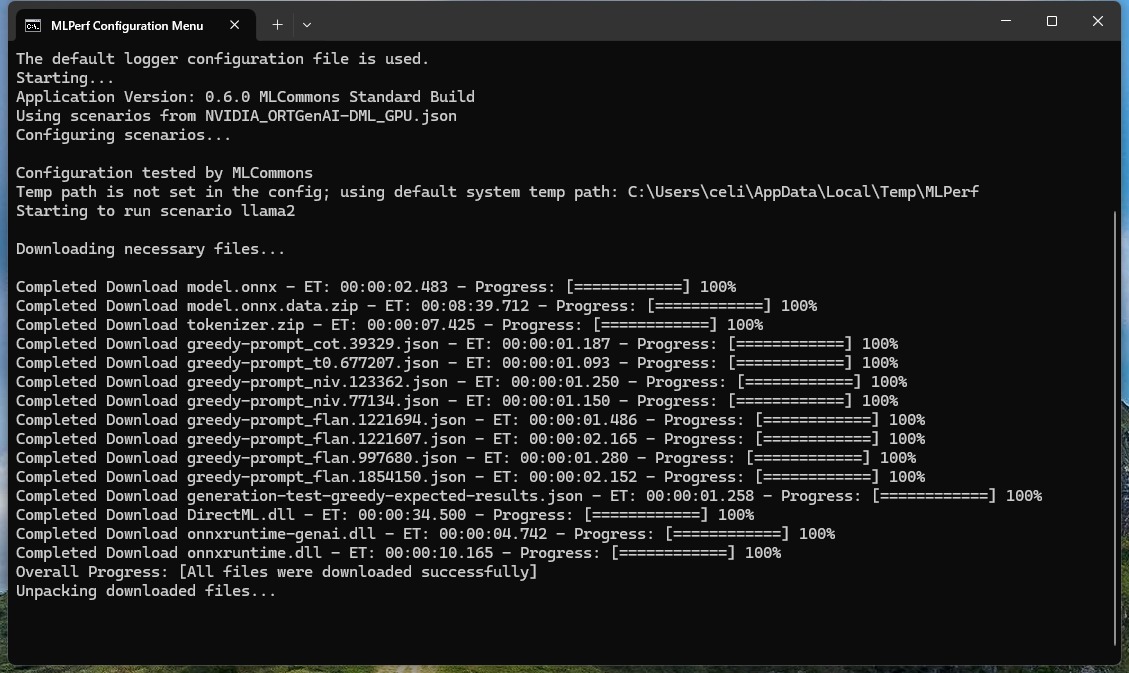
同時(shí)運(yùn)行也相當(dāng)簡(jiǎn)單,只須要把ZIP緊縮包解壓后,運(yùn)行對(duì)應(yīng)顯卡的定名行即可,如應(yīng)用NVIDIA顯卡的用戶,直接右鍵【在終端中打開(kāi)】,輸入【\mlperf-windows.exe -c NVIDIA_ORTGenAI-DML_GPU.json】即進(jìn)入下載的定名行,當(dāng)下載完測(cè)試模型之后,即開(kāi)端運(yùn)行測(cè)試。
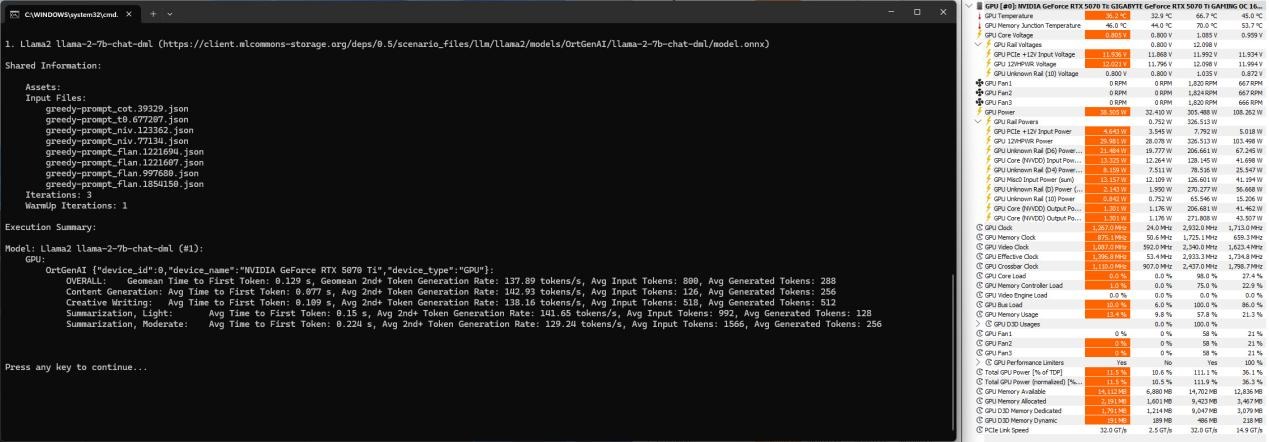
技嘉GeForce RTX 5070 Ti GAMING OC 魔鷹 16G顯卡測(cè)試出來(lái)的成果為上圖。這測(cè)試是基于llama-2-7b-chat-dml,較為關(guān)鍵的兩個(gè)數(shù)值為First Token響應(yīng)時(shí)光與Token平均生成速度。是以我們?cè)赗TX 50系列顯卡測(cè)試中也重要不雅察這兩數(shù)值的變更 。
面向花費(fèi)級(jí)和專業(yè)用戶的基準(zhǔn):UL Procyon AI Benchmark
UL Procyon是有名的基準(zhǔn)測(cè)試軟件[IT江湖]開(kāi)辟商UL Benchmarks(前身為Futuremark,3DMark的開(kāi)辟者)推出的一套專業(yè)基準(zhǔn)測(cè)試套件。

UL Procyon AI 文本生成基準(zhǔn)測(cè)試(AI Text Generation Benchmark)
之前我們應(yīng)用UL Procyon整機(jī)的 辦公臨盆率基準(zhǔn)測(cè)試、照片編輯基準(zhǔn)測(cè)試,以及視頻編輯基準(zhǔn)測(cè)試。但到了比來(lái)UL Procyon針對(duì)的AI方面的測(cè)試越來(lái)越多,且越來(lái)越專業(yè)化。是以我們也常拿此軟件[IT江湖]對(duì)顯卡進(jìn)行AI機(jī)能測(cè)試。
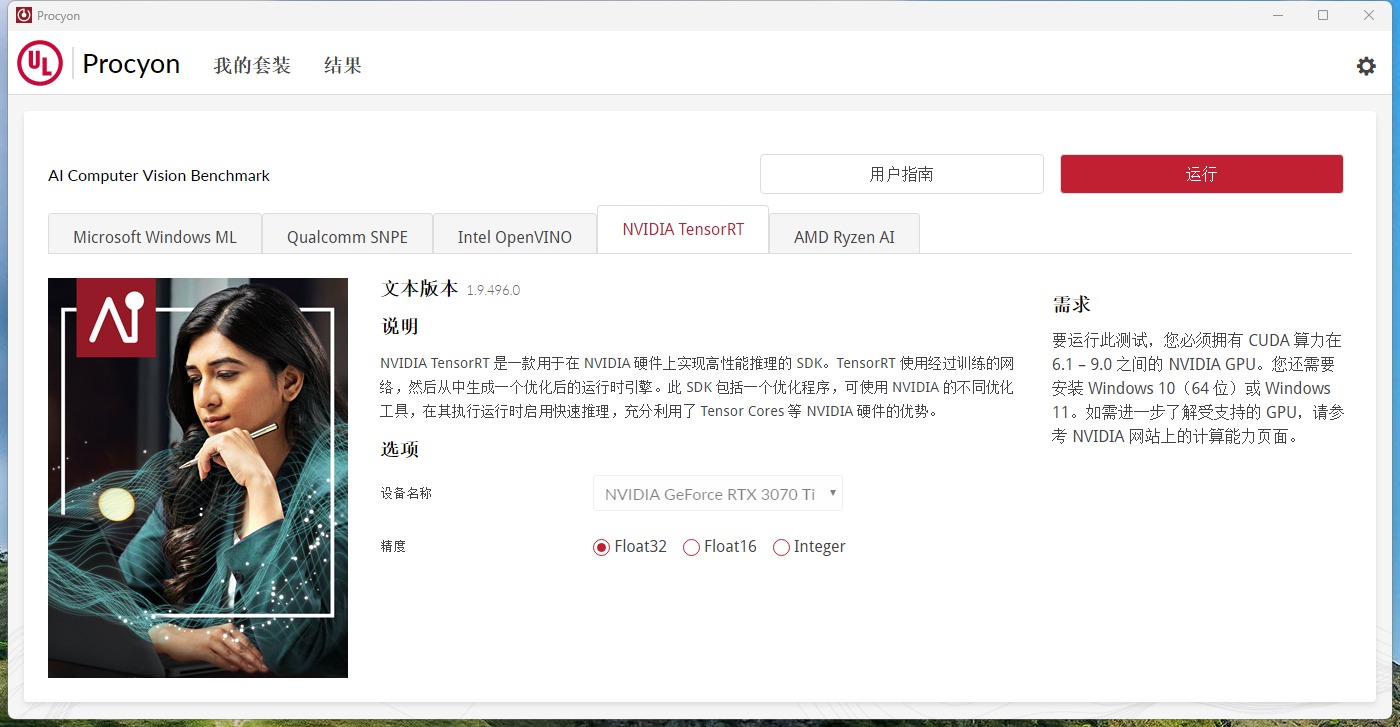
UL Procyon AI 計(jì)算機(jī)視覺(jué)基準(zhǔn)測(cè)試,測(cè)量Windows或macOS設(shè)備上AI推理引擎和專用AI硬件(如CPU、GPU、NPU)的機(jī)能,實(shí)用于企業(yè)、行業(yè)和媒體專業(yè)用戶。個(gè)中應(yīng)用先輩的神經(jīng)收集模型,如MobileNetV3、ResNet50、InceptionV4、DeepLabV3、YOLOv3和Real-ESRGAN,供給浮點(diǎn)(FP32/FP16)和整數(shù)(INT8)優(yōu)化版本。并支撐多種主流推理引擎,包含:NVIDIA TensorRT、Intel OpenVINO、Qualcomm SNPE、Microsoft Windows ML,以及Apple Core ML等。
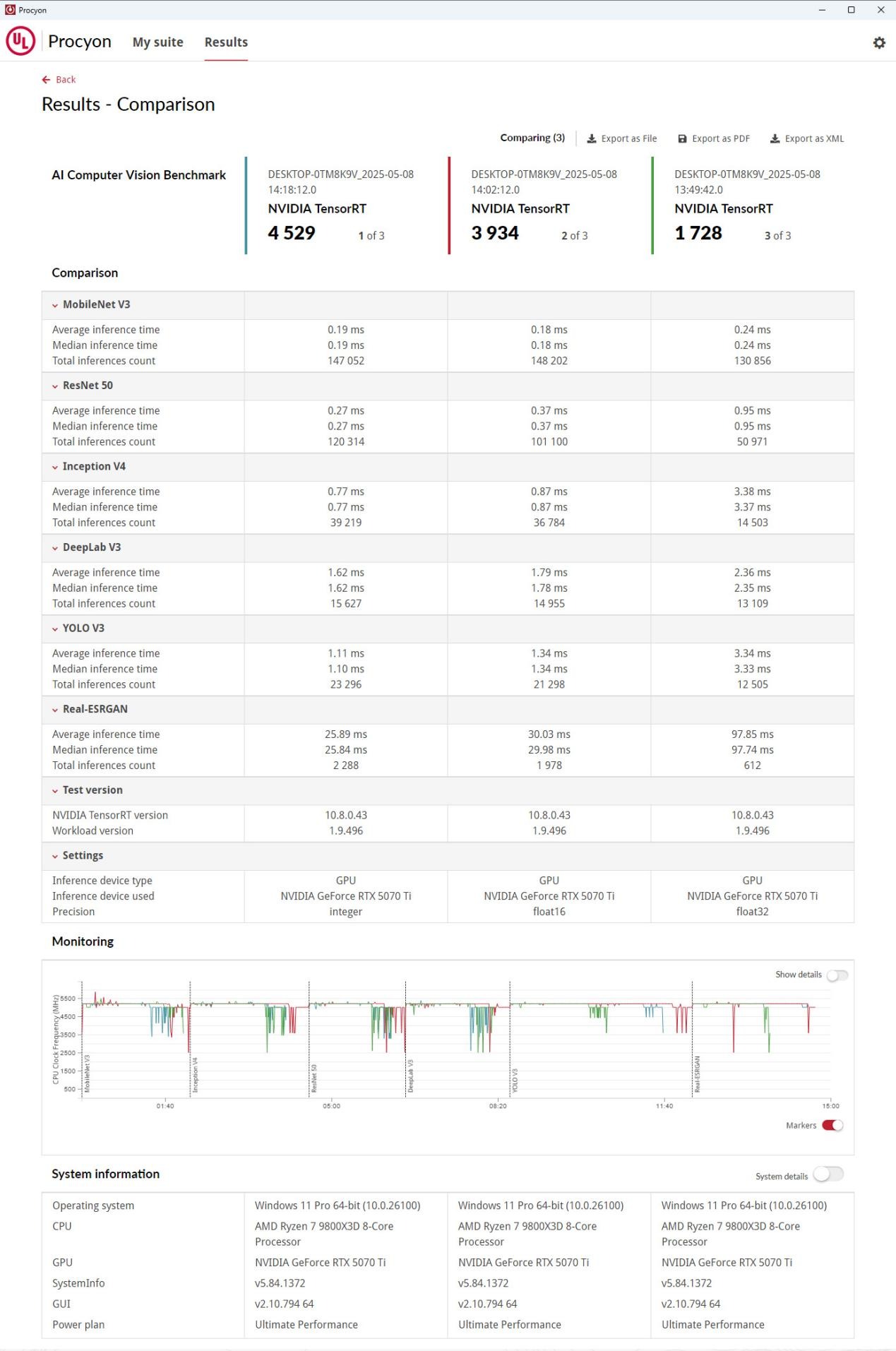
純真是針對(duì)NVIDIA TensorRT這種高機(jī)能推理的SDK,也給出了三種不合的精度:Float32、Float16,以及Integer。因?yàn)闇y(cè)試的神經(jīng)收集模型數(shù)量較多,是以AI 計(jì)算機(jī)視覺(jué)基準(zhǔn)測(cè)試給出來(lái)的具體測(cè)試成果也是較為復(fù)雜的,是以我們只須要看總分即可。
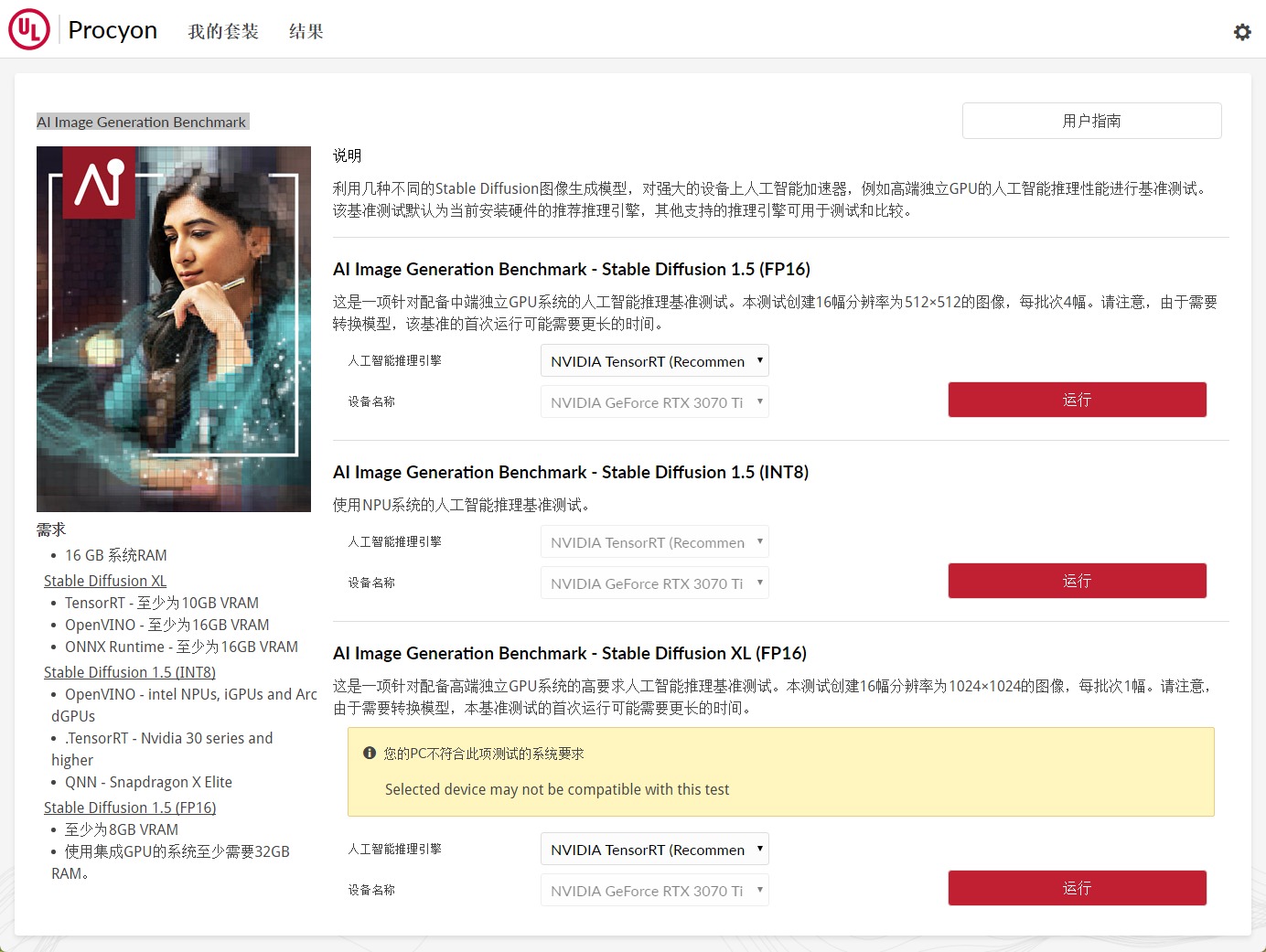
UL Procyon AI 圖像生成(AI Image Generation Benchmark)
UL Procyon AI 圖像生成評(píng)估高機(jī)能設(shè)備(特別是高端離散GPU)在AI圖像生成義務(wù)中的推理機(jī)能,實(shí)用于須要重型AI工作負(fù)載的場(chǎng)景。重要針對(duì)Windows,支撐AMD、Intel、NVIDIA的離散GPU,基于Stable Diffusion模型,生成文本到圖像的AI義務(wù),應(yīng)用標(biāo)準(zhǔn)化的文本提示確保一致性和靠得住性。
FLOPS (Floating Point Operations Per Second): 每秒浮點(diǎn)運(yùn)算次數(shù),衡量處理器履行浮點(diǎn)計(jì)算的才能。常見(jiàn)的精度有FP32(單精度)、FP16(半精度)、BF16(BFloat16)。

同樣測(cè)試模塊包含三個(gè):Stable Diffusion XL (FP16):最苛刻的測(cè)試,僅實(shí)用于最新高端GPU;Stable Diffusion 1.5 (FP16):合適中端離散GPU;Stable Diffusion 1.5 (INT8):針對(duì)低功耗設(shè)備(如NPU)。
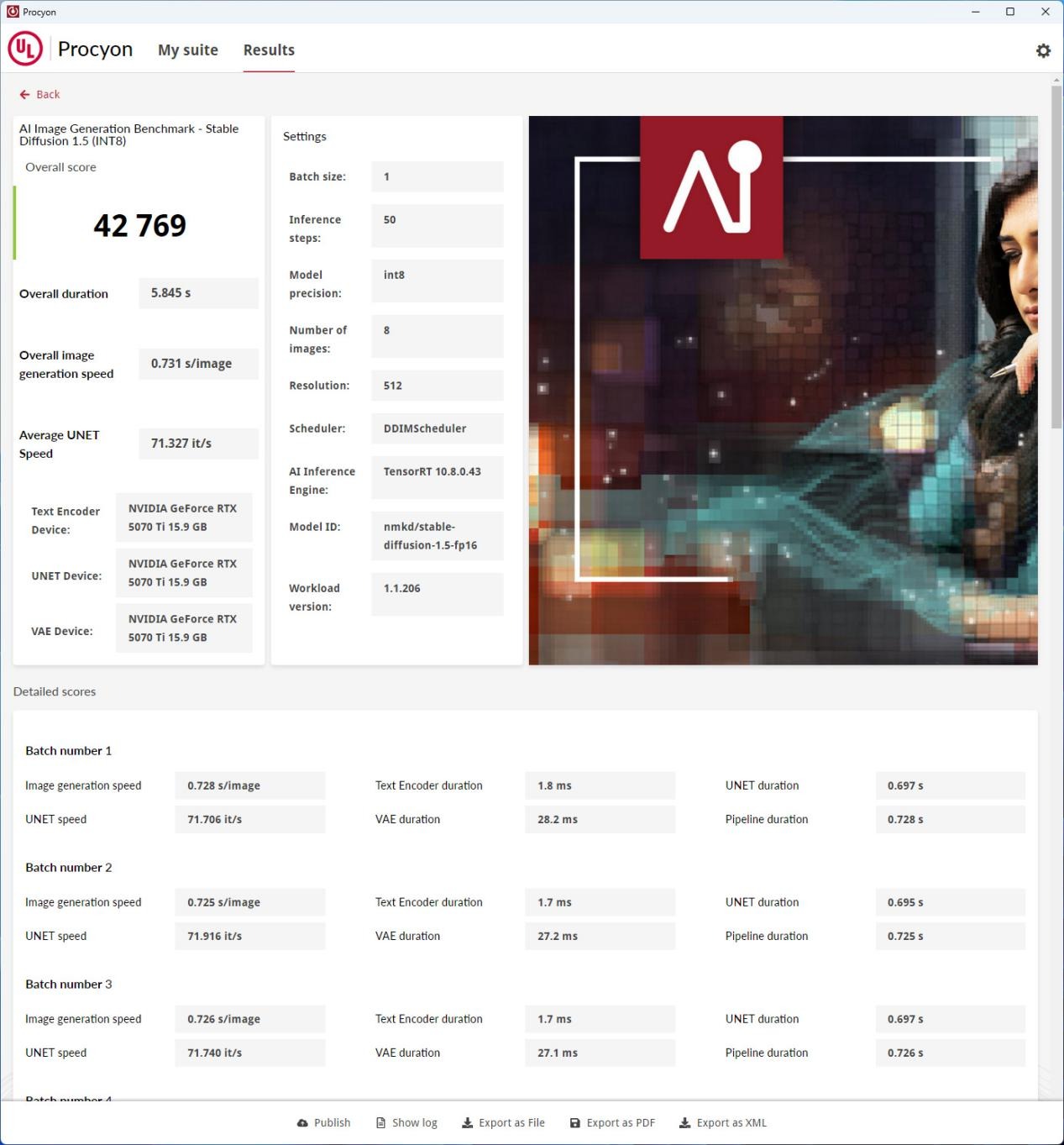
尤其是Stable Diffusion XL (FP16)測(cè)試生成的是1024 x 1024分辨率的圖片,對(duì)顯卡請(qǐng)求較高。若顯卡算力與顯存容量不足,基本上出來(lái)的運(yùn)行成果出現(xiàn)0分或者是缺點(diǎn)提示,那就證實(shí)你顯卡機(jī)能不足夠進(jìn)行此測(cè)試。而UL Procyon AI 圖像生成基準(zhǔn)測(cè)試中,我們除了要留心機(jī)能總特別,我們還一般會(huì)拿Overall duration - 總耗時(shí)、Overall image generation speed - 整體圖像生成速度,以及Average UNET Speed - 平均UNET速度來(lái)做比較。
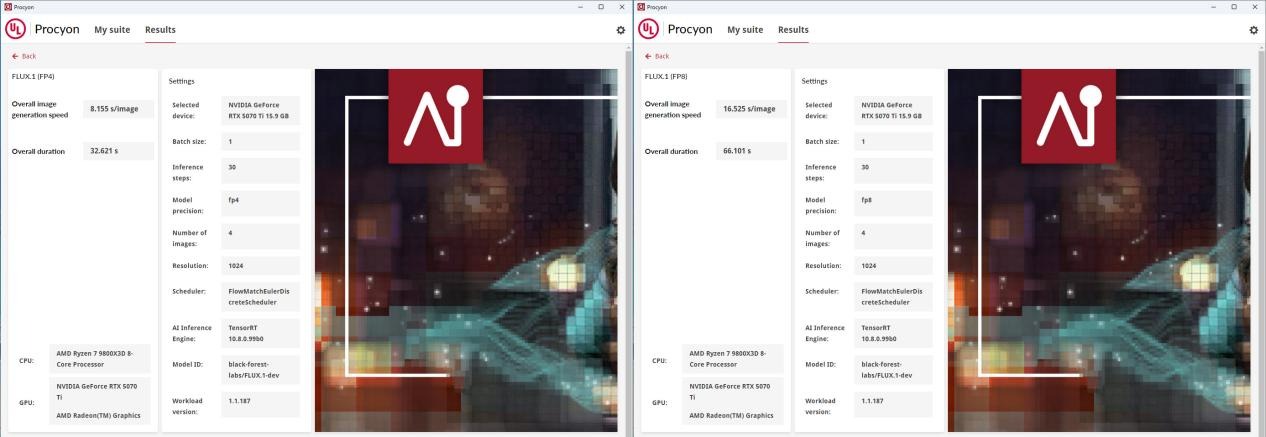
當(dāng)然RTX 50系列顯卡最大年夜的優(yōu)勢(shì)就在于支撐FP4精度的模型,而NVIDIA供給的Procyon-models_Flux1DEV_ONNX測(cè)試DEMO就是搶先可以或許讓我們體驗(yàn)一把FP4精度模型的優(yōu)勢(shì)。如上圖一樣可看到,同樣的測(cè)試設(shè)備和情況下,F(xiàn)P4精度速度明顯比FP8精度模型生成圖片的速度快了一半,同時(shí)其圖片質(zhì)量也獲得較好地包管。
UL Procyon AI 文本生成基準(zhǔn)測(cè)試,評(píng)估本地大年夜說(shuō)話模型(LLM)的AI推理機(jī)能,簡(jiǎn)化復(fù)雜LLM測(cè)試流程,實(shí)用于企業(yè)IT和硬件評(píng)估。基于多種LLM模型的文本生成義務(wù),測(cè)試支撐模型:Phi-3.5-mini、Mistral-7B、Llama-3.1-8B、Llama-2-13B。
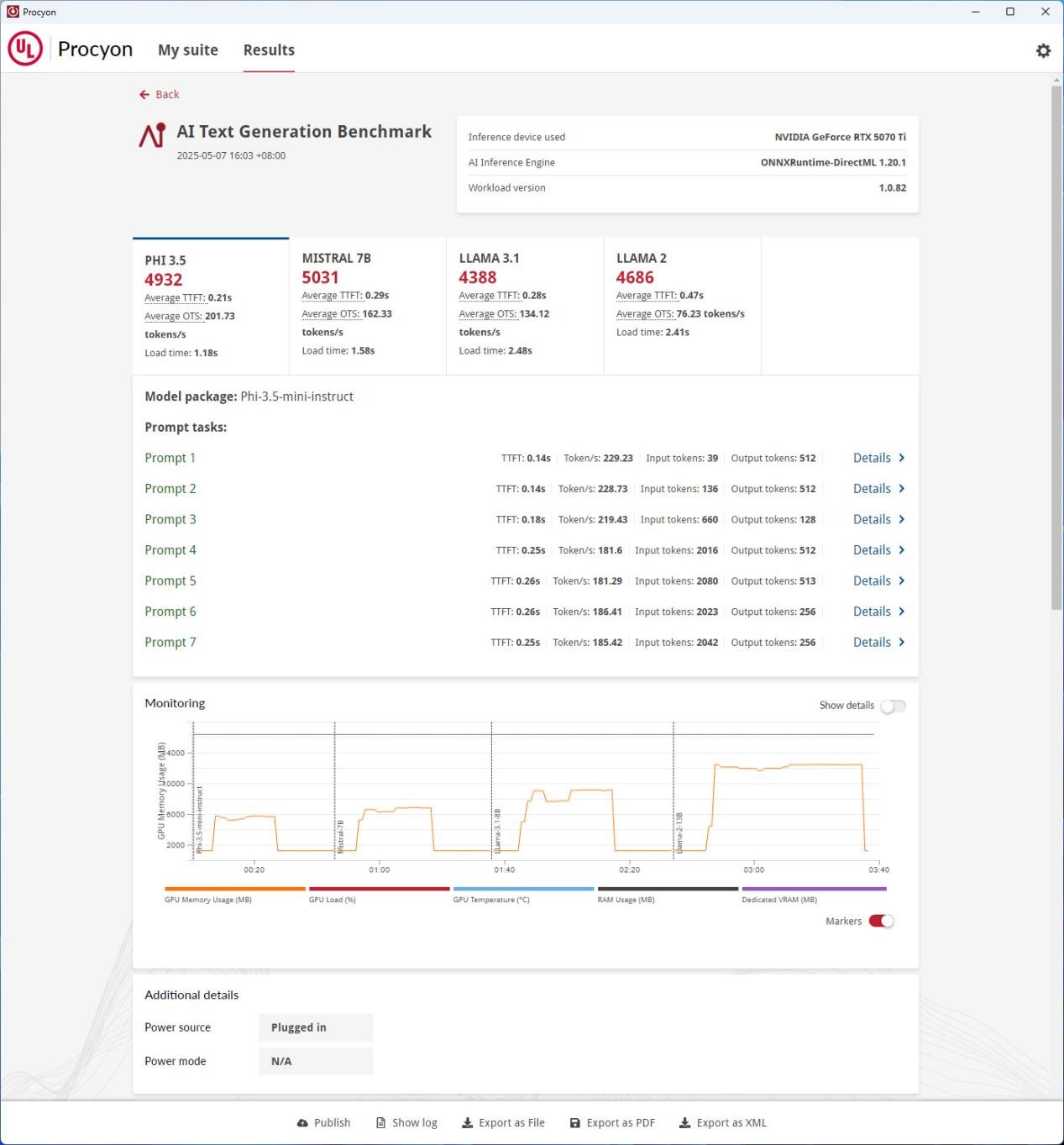
如上圖一樣,AI 文本生成基準(zhǔn)測(cè)試并沒(méi)有總分?jǐn)?shù),而是針對(duì)每個(gè)大年夜說(shuō)話模型給出總結(jié)分?jǐn)?shù)、平均首Token延遲時(shí)光(TTFT)、平均Token生成速度(OTS),以及加載時(shí)光。
當(dāng)然UL Procyon是須要額外花錢(qián)或者是申請(qǐng)授權(quán)才能讓你應(yīng)用測(cè)試的,那沒(méi)有和MLPerf Client一樣免費(fèi)的測(cè)試軟件[IT江湖],那天然是有的――LM Studio。LM Studio供給了一個(gè)用戶友愛(ài)的圖形界面,集成了模型發(fā)明、下載、加載、運(yùn)行以及經(jīng)由過(guò)程類似ChatGPT的聊天界面進(jìn)行交互的功能,更重要的是LM Studio還能支撐多GPU。
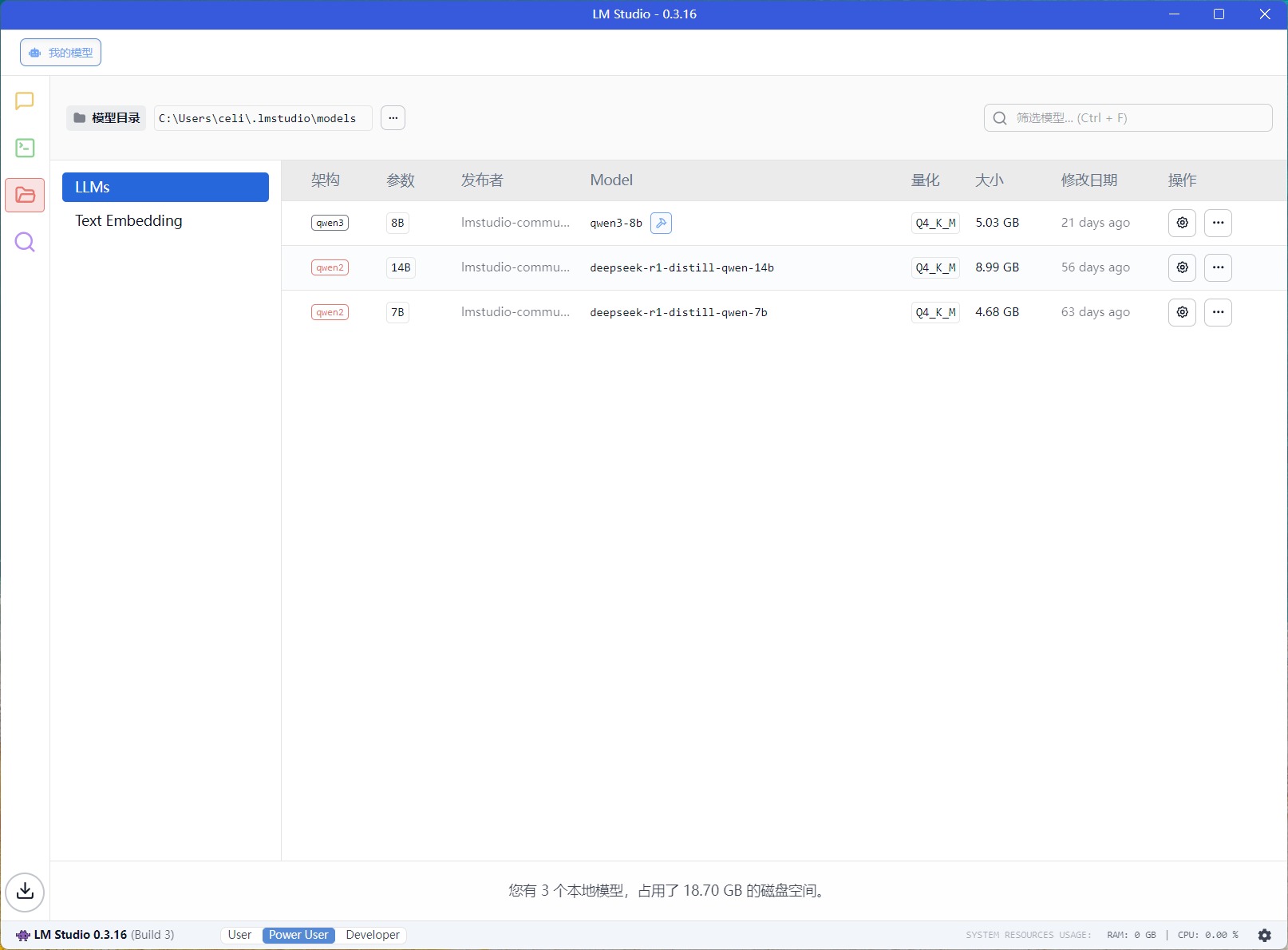
如許我們只須要下載對(duì)應(yīng)的測(cè)試模型,同樣的問(wèn)題設(shè)定與軟件[IT江湖]設(shè)置,就可以知道不合級(jí)別顯卡的首Token延遲時(shí)光(TTFT)與平均Token生成速度(OTS)。

總結(jié):
RTX 50系列顯卡的到來(lái),再次印證了花費(fèi)級(jí)顯卡正從“游戲?qū)佟毕颉巴ㄓ糜?jì)算與AI加快平臺(tái)”的計(jì)謀轉(zhuǎn)型。AI基準(zhǔn)測(cè)試對(duì)象,如同精準(zhǔn)的標(biāo)尺,贊助我們量化這些“鋼鐵猛獸”的“聰明”程度,懂得它們?cè)诓缓螦I應(yīng)用處景下的潛能。

對(duì)于通俗花費(fèi)者而言,懂得這些測(cè)試對(duì)象及其衡量標(biāo)準(zhǔn),有助于在選購(gòu)新顯卡時(shí),不再僅僅存眷游戲幀數(shù),更能洞察其在內(nèi)容創(chuàng)作、AI應(yīng)用等新興范疇的價(jià)值。對(duì)于行業(yè)而言,標(biāo)準(zhǔn)化的AI測(cè)試促進(jìn)了技巧的公平競(jìng)爭(zhēng)和持續(xù)立異。
UL Procyon AI 計(jì)算機(jī)視覺(jué)基準(zhǔn)測(cè)試(AI Computer Vision Benchmark)

將來(lái)已來(lái),AI算力不再是錦上添花的附加功能,而是定義下一代花費(fèi)級(jí)顯卡核心競(jìng)爭(zhēng)力的關(guān)鍵地點(diǎn)。無(wú)論是NVIDIA照樣AMD,誰(shuí)能在AI的賽道上供給更強(qiáng)大年夜、更高效、更易用的解決籌劃,誰(shuí)就更能博得用戶和市場(chǎng)的青睞。
來(lái)源:太平洋電腦網(wǎng)